 | Chapter 2 |  |

| Chapter 2 | |
Contents:
The Domain Name Space
The Internet Domain Name Space
Delegation
Name Servers and Zones
Resolvers
Resolution
Caching
"... and what is the use of a book," thought Alice, "without pictures or conversations?"
The Domain Name System is basically a database of host information. Admittedly, you get a lot with that: funny dotted names, networked name servers, a shadowy "name space." But keep in mind that, in the end, the service DNS provides is information about internet hosts.
We've already covered some important aspects of DNS, including its client-server architecture and the structure of the DNS database. However, we haven't gone into much detail, and we haven't explained the nuts and bolts of DNS's operation.
In this chapter, we'll explain and illustrate the mechanisms that make DNS work. We'll also introduce the terms you'll need to know to read the rest of the book (and to converse intelligently with your fellow domain administrators).
First, though, let's take a more detailed look at concepts introduced in the previous chapter. We'll try to add enough detail to spice it up a little.
DNS's distributed database is indexed by domain names. Each domain name is essentially just a path in a large inverted tree, called the domain name space. The tree's hierarchical structure, shown in Figure 2.1, is similar to the structure of the UNIX filesystem. The tree has a single root at the top.[1] In the UNIX filesystem, this is called the root directory, represented by a slash ("/"). DNS simply calls it "the root." Like a filesystem, DNS's tree can branch any number of ways at each intersection point, called a node. The depth of the tree is limited to 127 levels (a limit you're not likely to reach).
[1] Clearly this is a computer scientist's tree, not a botanist's.
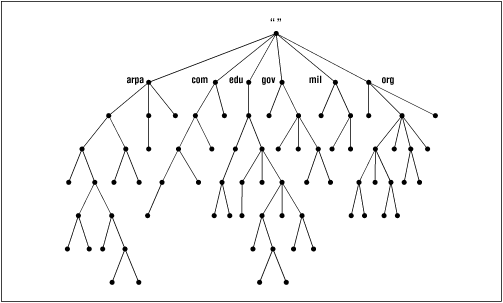
Each node in the tree has a text label (without dots) that can be up to 63 characters long. A null (zero-length) label is reserved for the root. The full domain name of any node in the tree is the sequence of labels on the path from that node to the root. Domain names are always read from the node toward the root ("up" the tree), and with dots separating the names in the path.
If the root node's label actually appears in a node's domain name, the name looks as though it ends in a dot, as in "www.oreilly.com.". (It actually ends with a dot - the separator - and the root's null label.) When the root node's label appears by itself, it is written as a single dot, ".", for convenience. Consequently, some software interprets a trailing dot in a domain name to indicate that the domain name is absolute. An absolute domain name is written relative to the root, and unambiguously specifies a node's location in the hierarchy. An absolute domain name is also referred to as a fully qualified domain name, often abbreviated FQDN. Names without trailing dots are sometimes interpreted as relative to some domain other than the root, just as directory names without a leading slash are often interpreted as relative to the current directory.
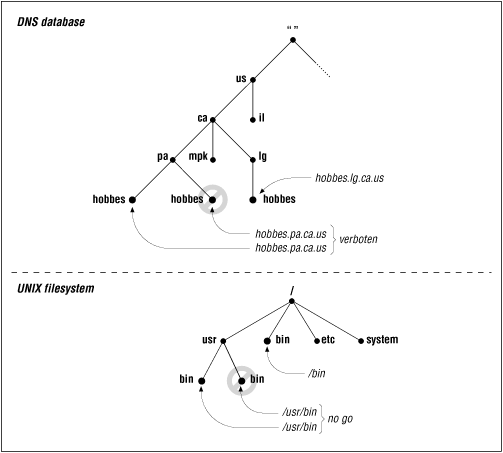
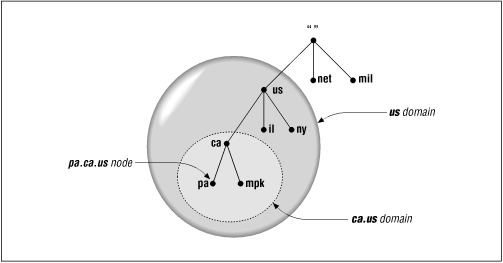
DNS requires that sibling nodes - nodes that are children of the same parent - have different labels. This restriction guarantees that a domain name uniquely identifies a single node in the tree. The restriction really isn't a limitation, because the labels only need to be unique among the children, not among all the nodes in the tree. The same restriction applies to the UNIX filesystem: You can't give two sibling directories the same name. Just as you can't have two hobbes.pa.ca.us nodes in the name space, you can't have two /usr/bin directories (Figure 2.2). You can, however, have both a hobbes.pa.ca.us node and a hobbes.lg.ca.us, as you can have both a /bin directory and a /usr/bin directory.
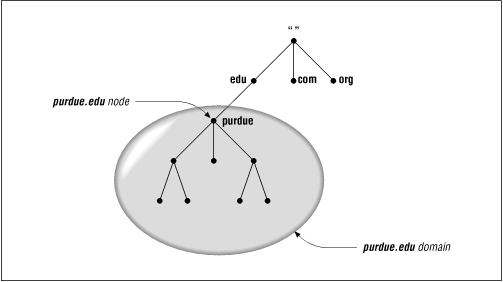
A domain is simply a subtree of the domain name space. The domain name of a domain is the same as the domain name of the node at the very top of the domain. So, for example, the top of the purdue.edu domain is a node named purdue.edu, as shown in Figure 2.3.
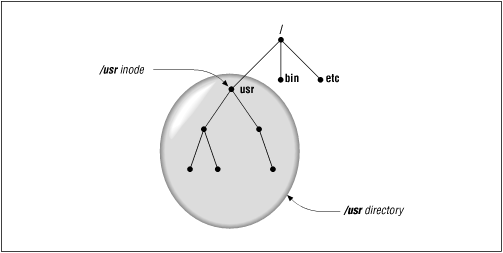
Likewise, in a filesystem, at the top of the /usr directory, you'd expect to find a node called /usr, as shown in Figure 2.4.
Any domain name in the subtree is considered a part of the domain. Because a domain name can be in many subtrees, a domain name can also be in many domains. For example, the domain name pa.ca.us is part of the ca.us domain and also part of the us domain, as shown in Figure 2.5.
So in the abstract, a domain is just a subtree of the domain name space. But if a domain is simply made up of domain names and other domains, where are all the hosts? Domains are groups of hosts, right?
The hosts are there, represented by domain names. Remember, domain names are just indexes into the DNS database. The "hosts" are the domain names that point to information about individual hosts. And a domain contains all the hosts whose domain names are within the domain. The hosts are related logically, often by geography or organizational affiliation, and not necessarily by network or address or hardware type. You might have ten different hosts, each of them on a different network and each one perhaps even in a different country, all in the same domain.[2]
[2] One note of caution: Don't confuse domains in the Domain Name System with domains in Sun's Network Information Service (NIS). Though an NIS domain also refers to a group of hosts, and both types of domains have similarly structured names, the concepts are quite different. NIS uses hierarchical names, but the hierarchy ends there: hosts in the same NIS domain share certain data about hosts and users, but they can't navigate the NIS name space to find data in other NIS domains. NT domains, which provide account management and security services, also don't have any relationship to DNS domains.
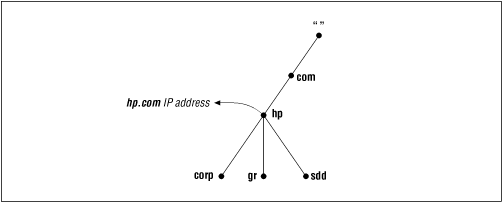
Domain names at the leaves of the tree generally represent individual hosts, and they may point to network addresses, hardware information, and mail routing information. Domain names in the interior of the tree can name a host and can point to information about the domain. Interior domain names aren't restricted to one or the other. They can represent both the domain they correspond to and a particular host on the network. For example, hp.com is both the name of the Hewlett-Packard Company's domain and the domain name of a host that runs HP's main web server.
The type of information retrieved when you use a domain name depends on the context in which you use it. Sending mail to someone at hp.com would return mail routing information, while telneting to the domain name would look up the host information (in Figure 2.6, for example, hp.com's IP address).[3]
[3] The terms domain and subdomain are often used interchangeably, or nearly so, in DNS and BIND documentation. Here, we use subdomain only as a relative term: a domain is a subdomain of another domain if the root of the subdomain is within the domain.
A simple way of deciding whether a domain is a subdomain of another domain is to compare their domain names. A subdomain's domain name ends with the domain name of its parent domain. For example, the domain la.tyrell.com must be a subdomain of tyrell.com because la.tyrell.com ends with tyrell.com. Similarly, it's a subdomain of com, as is tyrell.com.
Besides being referred to in relative terms, as subdomains of other domains, domains are often referred to by level. On mailing lists and in Usenet newsgroups, you may see the terms top-level domain or second-level domain bandied about. These terms simply refer to a domain's position in the domain name space:
The data associated with domain names are contained in resource records, or RRs. Records are divided into classes, each of which pertains to a type of network or software. Currently, there are classes for internets (any TCP/IP-based internet), networks based on the Chaosnet protocols, and networks that use Hesiod software. (Chaosnet is an old network of largely historic significance.)
The internet class is by far the most popular. (We're not really sure if anyone still uses the Chaosnet class, and use of the Hesiod class is mostly confined to MIT.) We concentrate here on the internet class.
Within a class, records also come in several types, which correspond to the different varieties of data that may be stored in the domain name space. Different classes may define different record types, though some types may be common to more than one class. For example, almost every class defines an address type. Each record type in a given class defines a particular record syntax, which all resource records of that class and type must adhere to. (For details on all internet resource record types and their syntaxes, see Appendix A, DNS Message Format and Resource Records.)
If this information seems sketchy, don't worry - we'll cover the records in the internet class in more detail later. The common records are described in Chapter 4, Setting Up BIND, and a comprehensive list is included as part of Appendix A.
|  | |
| 1.5 Must I Use DNS? |  | 2.2 The Internet Domain Name Space |