 |  |

| |
Shell Scripts and Functions
Shell Variables
Compound Variables
Indirect Variable References (namerefs)
String Operators
Command Substitution
Advanced Examples: pushd and popd
If you have become familiar with the customization techniques we presented in the previous chapter, you have probably run into various modifications to your environment that you want to make but can't -- yet. Shell programming makes these possible.
The Korn shell has some of the most advanced programming capabilities of any command interpreter of its type. Although its syntax is nowhere near as elegant or consistent as that of most conventional programming languages, its power and flexibility are comparable. In fact, the Korn shell can be used as a complete environment for writing software prototypes.
Some aspects of Korn shell programming are really extensions of the customization techniques we have already seen, while others resemble traditional programming language features. We have structured this chapter so that if you aren't a programmer, you can read this chapter and do quite a bit more than you could with the information in the previous chapter. Experience with a conventional programming language like Pascal or C is helpful (though not strictly necessary) for subsequent chapters. Throughout the rest of the book, we will encounter occasional programming problems, called tasks, whose solutions make use of the concepts we cover.
A script, or file that contains shell commands, is a shell program. Your .profile and environment files, discussed in Chapter 3, are shell scripts.
You can create a script using the text editor of your choice. Once you have created one, there are a number of ways to run it. One, which we have already covered, is to type . scriptname (i.e., the command is a dot). This causes the commands in the script to be read and run as if you typed them in.
Two more ways are to type ksh script or ksh < script. These explicitly invoke the Korn shell on the script, requiring that you (and your users) be aware that they are scripts.
The final way to run a script is simply to type its name and hit ENTER, just as if you were invoking a built-in command. This, of course, is the most convenient way. This method makes the script look just like any other Unix command, and in fact several "regular" commands are implemented as shell scripts (i.e., not as programs originally written in C or some other language), including spell, man on some systems, and various commands for system administrators. The resulting lack of distinction between "user command files" and "built-in commands" is one factor in Unix's extensibility and, hence, its favored status among programmers.
You can run a script by typing its name only if . (the current directory) is part of your command search path, i.e., is included in your PATH variable (as discussed in Chapter 3). If . isn't on your path, you must type ./scriptname, which is really the same thing as typing the script's relative pathname (see Chapter 1).
Before you can invoke the shell script by name, you must also give it "execute" permission. If you are familiar with the Unix filesystem, you know that files have three types of permissions (read, write, and execute) and that those permissions apply to three categories of user (the file's owner, a group of users, and everyone else). Normally, when you create a file with a text editor, the file is set up with read and write permission for you and read-only permission for everyone else.[49]
[49] This actually depends on the setting of your umask, an advanced feature described in Chapter 10.
Therefore you must give your script execute permission explicitly, by using the chmod(1) command. The simplest way to do this is like so:
chmod +x scriptname
Your text editor preserves this permission if you make subsequent changes to your script. If you don't add execute permission to the script, and you try to invoke it, the shell prints the message:
ksh: scriptname: cannot execute [Permission denied]
But there is a more important difference between the two ways of running shell scripts. While the "dot" method causes the commands in the script to be run as if they were part of your login session, the "just the name" method causes the shell to do a series of things. First, it runs another copy of the shell as a subprocess. The shell subprocess then takes commands from the script, runs them, and terminates, handing control back to the parent shell.
Figure 4-1 shows how the shell executes scripts. Assume you have a simple shell script called fred that contains the commands bob and dave. In Figure 4-1.a, typing . fred causes the two commands to run in the same shell, just as if you had typed them in by hand. Figure 4-1.b shows what happens when you type just fred: the commands run in the shell subprocess while the parent shell waits for the subprocess to finish.
You may find it interesting to compare this with the situation in Figure 4-1.c, which shows what happens when you type fred &. As you will recall from Chapter 1, the & makes the command run in the background, which is really just another term for "subprocess." It turns out that the only significant difference between Figure 4-1.c and Figure 4-1.b is that you have control of your terminal or workstation while the command runs -- you need not wait until it finishes before you can enter further commands.
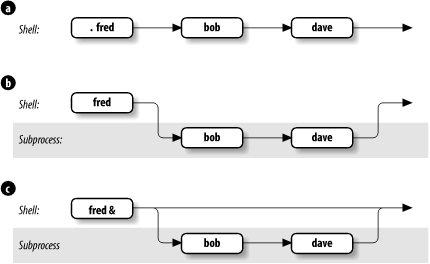
There are many ramifications to using shell subprocesses. An important one is that the exported environment variables that we saw in the last chapter (e.g., TERM, LOGNAME, PWD) are known in shell subprocesses, whereas other shell variables (such as any that you define in your .profile without an export statement) are not.
Other issues involving shell subprocesses are too complex to go into now; see Chapter 7 and Chapter 8 for more details about subprocess I/O and process characteristics, respectively. For now, just bear in mind that a script normally runs in a shell subprocess.
The Korn shell's function feature is an expanded version of a similar facility in the System V Bourne shell and a few other shells. A function is sort of a script-within-a-script; you use it to define some shell code by name and store it in the shell's memory, to be invoked and run later.
Functions improve the shell's programmability significantly, for two main reasons. First, when you invoke a function, it is already in the shell's memory (except for automatically loaded functions; see Section 4.1.1.1, later in this chapter); therefore a function runs faster. Modern computers have plenty of memory, so there is no need to worry about the amount of space a typical function takes up. For this reason, most people define as many functions as possible rather than keep lots of scripts around.
The other advantage of functions is that they are ideal for organizing long shell scripts into modular "chunks" of code that are easier to develop and maintain. If you aren't a programmer, ask one what life would be like without functions (also called procedures or subroutines in other languages) and you'll probably get an earful.
To define a function, you can use either one of two forms:
function functname { Korn shell semantics
shell commands
}
or:
functname () { POSIX semantics
shell commands
}
The first form provides access to the full power and programmability of the Korn shell. The second is compatible with the syntax for shell functions introduced in the System V Release 2 Bourne shell. This form obeys the semantics of the POSIX standard, which are less powerful than full Korn shell-style functions. (We discuss the differences in detail shortly.) We always use the first form in this book. You can delete a function definition with the command unset -f functname.
When you define a function, you tell the shell to store its name and definition (i.e., the shell commands it contains) in memory. If you want to run the function later, just type in its name followed by any arguments, as if it were a shell script.
You can find out what functions are defined in your login session by typing functions.[50] (Note the s at the end of the command name.) The shell will print not just the names but also the definitions of all functions, in alphabetical order by function name. Since this may result in long output, you might want to pipe the output through more or redirect it to a file for examination with a text editor.
[50] This is actually an alias for typeset -f; see Chapter 6.
Apart from the advantages, there are two important differences between functions and scripts. First, functions do not run in separate processes, as scripts do when you invoke them by name; the "semantics" of running a function are more like those of your .profile when you log in or any script when invoked with the "dot" command. Second, if a function has the same name as a script or executable program, the function takes precedence.
This is a good time to show the order of precedence for the various sources of commands. When you type a command to the shell, it looks in the following places until it finds a match:
Keywords, such as function and several others (e.g., if and for) that we will see in Chapter 5
Aliases (although you can't define an alias whose name is a shell keyword, you can define an alias that expands to a keyword, e.g., alias aslongas=while; see Chapter 7 for more details)
Special built-ins, such as break and continue (the full list is . (dot), :, alias, break, continue, eval, exec, exit, export, login, newgrp, readonly, return, set, shift, trap, typeset, unalias, and unset)
Functions
Non-special built-ins, such as cd and whence
Scripts and executable programs, for which the shell searches in the directories listed in the PATH environment variable
We'll examine this process in more detail in the section on command-line processing in Chapter 7.
If you need to know the exact source of a command, there is an option to the whence built-in command that we saw in Chapter 3. whence by itself will print the pathname of a command if the command is a script or executable program, but it will only parrot the command's name back if it is anything else. But if you type whence -v commandname, you get more complete information, such as:
$ whence -v cd cd is a shell builtin $ whence -v function function is a keyword $ whence -v man man is a tracked alias for /usr/bin/man $ whence -v ll ll is an alias for 'ls -l'
For compatibility with the System V Bourne shell, the Korn shell predefines the alias type='whence -v'. This definitely makes the transition to the Korn shell easier for long-time Bourne shell users; type is similar to whence. The whence command actually has several options, described in Table 4-1.
| Option | Meaning |
|---|---|
| -a | Print all interpretations of given name. |
| -f | Skip functions in search for name. |
| -p | Search $PATH, even if name is a built-in or function. |
| -v | Print more verbose description of name. |
Throughout the remainder of this book we refer mainly to scripts, but unless we note otherwise, you should assume that whatever we say applies equally to functions.
At first glance, it would seem that the best place to put your own function definitions is in your .profile or environment file. This is great for interactive use, since your login shell reads ~/.profile, and other interactive shells read the environment file. However, any shell scripts that you write don't read either file. Furthermore, as your collection of functions grows, so too do your initialization files, making them hard to work with.
ksh93 works around both of these issues by integrating the search for functions with the search for commands. Here's how it works:
Create a directory to hold your function definitions. This can be your private bin directory, or you may wish to have a separate directory, such as ~/funcs. For the sake of discussion, assume the latter.
In your .profile file, add this directory to both the variables PATH and FPATH:
PATH=$PATH:~/funcs FPATH=~/funcs export PATH FPATH
In ~/funcs, place the definition of each of your functions into a separate file. Each function's file should have the same name as the function:
$ mkdir ~/funcs
$ cd ~/funcs
$ cat > whoson
# whoson --- create a sorted list of logged-on users
function whoson {
who | awk '{ print $1 }' | sort -u
}
^D
Now, the first time you type whoson, the shell looks for a command named whoson using the search order described earlier. It will not be found as a special-built-in, as a function, or as a regular built-in. The shell then starts a search along $PATH. When it finally finds ~/funcs/whoson, the shell notices that ~/funcs is also in $FPATH. ("Aha!" says the shell.) When this is the case, the shell expects to find the definition of the function named whoson inside the file. It reads and executes the entire contents of the file and only then runs the function whoson, with any supplied arguments. (If the file found in both $PATH and $FPATH doesn't actually define the function, you'll get a "not found" error message.)
The next time you type whoson, the function is already defined, so the shell finds it immediately, without the need for the path search.
Note that directories listed in FPATH but not in PATH won't be searched for functions, and that as of ksh93l, the current directory must be listed in FPATH via an explicit dot; a leading or trailing colon doesn't cause the current directory to be searched.
As a final wrinkle, starting with ksh93m, each directory named in PATH may contain a file named .paths. This file may contain comments and blank lines, and specialized variable assignments. The first allowed assignment is to FPATH, where the value should name an existing directory. If that directory contains a file whose name matches the function being searched for, that file is read and executed as if via the . (dot) command, and then the function is executed.
In addition, one other environment variable may be assigned to. The intended use of this is to specify a relative or absolute path for a library directory containing the shared libraries for executables in the current bin directory. On many Unix systems, this variable is LD_LIBRARY_PATH, but some systems have a different variable -- check your local documentation. The given value is prepended to the existing value of the variable when the command is executed. (This mechanism may open security holes. System administrators should use it with caution!)
For example, the AT&T Advanced Software Tools group that distributes ksh93 also has many other tools, often installed in a separate ast/bin directory. This feature allows the ast programs to find their shared libraries, without the user having to manually adjust LD_LIBRARY_PATH in the .profile file.[51] For example, if a command is found in /usr/local/ast/bin, and the .paths file in that directory contains the assignment LD_LIBRARY_PATH=../lib, the shell prepends /usr/local/ast/lib: to the value of LD_LIBRARY_PATH before running the command.
[51] ksh93 point releases h through l+ used a similar but more restricted mechanism, via a file named .fpath, and they hard-wired the setting of the library path variable. As this feature was not wide-spread, it was generalized into a single file starting with point release m.
Readers familiar with ksh88 will notice that this part of the shell's behavior has changed significantly. Since ksh88 always read the environment file, whether or not the shell was interactive, it was simplest to just put function definitions there. However, this could still yield a large, unwieldy file. To get around this, you could create files in one or more directories listed in $FPATH. Then, in the environment file, you would mark the functions as being autoloaded:
autoload whoson ...
Marking a function with autoload[52] tells the shell that this name is a function, and to find the definition by searching $FPATH. The advantage to this is that the function is not loaded into the shell's memory if it's not needed. The disadvantage is that you have to explicitly list all your functions in your environment file.
[52] autoload is actually an alias for typeset -fu.
ksh93's integration of PATH and FPATH searching thus simplifies the way you add shell functions to your personal shell function "library."
As mentioned earlier, functions defined using the POSIX syntax obey POSIX semantics and not Korn shell semantics:
functname () {
shell commands
}
The best way to understand this is to think of a POSIX function as being like a dot script. Actions within the body of the function affect all the state of the current script. In contrast, Korn shell functions have much less shared state with the parent shell, although they are not identical to totally separate scripts.
The technical details follow; they include information that we haven't covered yet. So come back and reread this section after you've learned about the typeset command in Chapter 6 and about traps in Chapter 8.
POSIX functions share variables with the parent script. Korn shell functions can have their own local variables.
POSIX functions share traps with the parent script. Korn shell functions can have their own local traps.
POSIX functions cannot be recursive (call themselves).[53] Korn shell functions can.
[53] This is a restriction imposed by the Korn shell, not by the POSIX standard.
When a POSIX function is run, $0 is not changed to the name of the function.
If you use the dot command with the name of a Korn shell function, that function will obey POSIX semantics, affecting all the state (variables and traps) of the parent shell:
$ function demo { Define a Korn shell function
> typeset myvar=3 Set a local variable myvar
> print "demo: myvar is $myvar"
> }
$ myvar=4 Set the global myvar
$ demo ; print "global: myvar is $myvar" Run the function
demo: myvar is 3
global: myvar is 4
$ . demo Run with POSIX semantics
demo: myvar is 3
$ print "global: myvar is $myvar" See the results
global: myvar is 3
|  | |
| 3.6. Customization Hints |  | 4.2. Shell Variables |

Copyright © 2003 O'Reilly & Associates. All rights reserved.