 |  |

| |
This section discusses datatypes derived from the xs:string primitive datatype as well as other datatypes that have a similar behavior (namely, xs:hexBinary, xs:base64Binary, xs:anyURI, xs:QName, and xs:NOTATION). These types are not expected to carry any quantifiable value (W3C XML Schema doesn't even expect to be able to sort them) and their value space is identical to their lexical space except when explicitly described otherwise. One should note that even though they are grouped in this section because they have a similar behavior, these primitive datatypes are considered quite different by the Recommendation.
The datatypes covered in this section are shown in Figure 4-2.
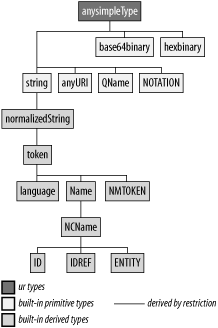
The two exceptions in whitespace processing (xs:string and xs:normalizedString) are string datatypes. One of the main differences between these types is the applied whitespace processing. To stress this difference, we will classify these types by their whitespace processing.
As expected, a string is a set of characters matching the definition given by XML 1.0, namely, "legal characters are tab, carriage return, line feed, and the legal characters of Unicode and ISO/IEC 10646."
The value of the following element:
<title lang="en"> Being a Dog Is a Full-Time Job </title>
is the full string:
Being a Dog Is a Full-Time Job
with all its tabs, and CR/LF if the title element is a type xs:string.
The lexical space of xs:normalizedString is the same as the lexical space of xs:string from which it is derived--except that since any occurrence of #x9 (tab), #xA (linefeed), and #xD (carriage return) are replaced by a #x20 (space), these three characters cannot be found in its lexical and value spaces.
The value of the same element:
<title lang="en"> Being a Dog Is a Full-Time Job </title>
is now the string:
Being a Dog Is a Full-Time Job
in which all the whitespaces have been replaced by spaces if the title element is a type xs:normalizedString.
TIP: There is no additional constraint on normalized strings. Any value that is a valid xs:string is also a valid xs:normalizedString. The difference is the whitespace processing that is applied when the lexical value is calculated.
Whitespace collapsing is performed after whitespace replacement by trimming the leading and trailing spaces and replacing all the contiguous occurrences of spaces with a single space. All the predefined datatypes (except, as we have seen, xs:string and xs:normalizedString) are whitespace collapsed.
We will classify tokens, binary formats, URIs, qualified names, notations, and all their derived types under this category. Although these datatypes share a number of properties, we must stress again that this categorization is done for the purpose of explanation and does not directly appear in the Recommendation.
The same element:
<title lang="en"> Being a Dog Is a Full-Time Job </title>
is still a valid xs:token, and its value is now the string:
Being a Dog Is a Full-Time Job
in which all the whitespaces have been replaced by spaces, any trailing spaces are removed, and contiguous sequences of spaces are replaced by single spaces.
TIP: As is the case with xs:normalizedString, there is no constraint on xs:token, and any value that is a valid xs:string is also a valid xs:token. The difference is the whitespace processing that is applied when the lexical value is calculated. This is not true of derived datatypes that have additional constraints on their lexical and value space. The restriction on the lexical spaces of xs:normalizedString is, therefore, a restriction by projection of their parsed space (different values of their parsed space are transformed into a single value of their lexical space), and not a restriction by invalidating values of their lexical space, as is the case for all the other predefined datatypes.
The predefined datatypes derived from xs:token are xs:language, xs:NMTOKEN, and xs:Name.
TIP: XML 1.0 gives the following definition of unparsed entities: "an unparsed entity is a resource whose contents may or may not be text, and if text, may be other than XML. Each unparsed entity has an associated notation, identified by name. Beyond a requirement that an XML processor make the identifiers for the entity and notation available to the application, XML places no constraints on the contents of unparsed entities." In practice, this mechanism has seldom been used, as the general usage is to define links to the resources that could be defined as unparsed entities.
W3C XML Schema itself has already given us some examples of QNames. When we write <xs:attribute name="lang" type="xs:language"/>, the type attribute is an xs:QName and its value is the tuple:
{"http://www.w3.org/2001/XMLSchema", "language"}because the URI:
"http://www.w3.org/2001/XMLSchema"
was assigned to the prefix "xs:". If there is no namespace declaration for this prefix, the type attribute is considered invalid.
The prefix of an xs:QName is optional. We are also able to write:
<xs:element ref="book" maxOccurs="unbounded"/>
in which the ref attribute is also a xs:QName and its value the tuple:
{NULL, "book"}because we haven't defined any default namespace. xs:QName does support default namespaces; if a default namespace is defined in the scope of this element, the value of its URI is used for this tuple.
As an example of this transformation, the href attribute of an XHTML link written as:
<a href="http://dmoz.org/World/Français/"> Word/Français </a>
would be converted to the value:
http://dmoz.org/World/Fran%e7ais/
in the value space.
The xs:anyURI datatype doesn't pay any attention to xml:base attributes that may have been defined in the document.
XML 1.0 is unable to hold binary content, which must be string-encoded before it can be included in a XML document. W3C XML Schema has defined two primary datatypes to support two encodings that are commonly used (BinHex and base64). These encodings may be used to include any binary content, including text formats whose content may be incompatible with the XML markup. Other binary text encodings may also be used (such as uuXXcode, Quote Printable, BinHex, aencode, or base85, to name a few), but their value would not be recognized by W3C XML Schema.
A UTF-8 XML header such as:
<?xml version="1.0" encoding="UTF-8"?>
that is encoded as xs:hexBinary would be:
3f3c6d78206c657673726f693d6e3122302e20226e656f636964676e223d54552d4622383e3f
The same header encoded as xs:base64Binary would be:
PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0iVVRGLTgiPz4NCg==
The W3C XML Schema Recommendation missed the fact that RFC 2045 requests a line break every 76 characters. This should be clarified in an errata. The consequence of these line breaks being thought of as optional by W3C XML Schema, is that the lexical and value spaces of xs:base64Binary cannot be considered identical.
|  | |
| 4.2. Whitespace Processing |  | 4.4. Numeric Datatypes |

Copyright © 2002 O'Reilly & Associates. All rights reserved.