 |  |

| |
Lexical and Value Spaces
Whitespace Processing
String Datatypes
Numeric Datatypes
Date and Time Datatypes
List Types
What About anySimpleType?
Back to Our Library
W3C XML Schema provides an extensive set of predefined datatypes. W3C XML Schema derives many of these predefined datatypes from a smaller set of "primitive" datatypes that have a specific meaning and semantic and cannot be derived from other types. We will see how we can use these types to define our own datatypes by derivation to meet more specific needs in the next chapter.
Figure 4-1 provides a map of predefined datatypes and the relationships between them.
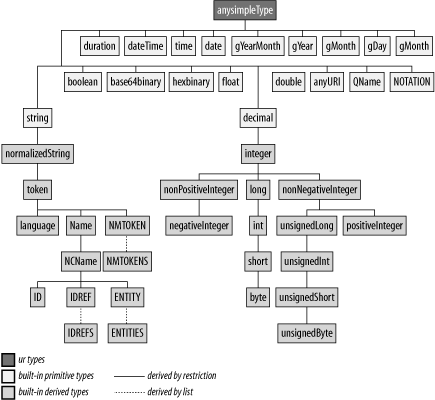
W3C XML Schema introduced a decoupling between the data, as it can be read from the instance documents (the "lexical space"), and the value, as interpreted according to the datatype (the "value space").
Before we can enter into the definition of these two spaces, we must examine the processing model and the transformations endured by a value written in a XML document before it is validated. Element and attribute content proceeds through the following steps during processing:
Each datatype has its own lexical and value spaces and its own rules to associate a lexical representation with a value; for many datatypes, a single value can have multiple lexical representations (for instance, the <xs:float> value "3.14116" can also be written equivalently as "03.14116," "3.141160," or ".314116E1"). This distinction is important since the basic operations performed on the values (such as equality testing or sorting) are done on the value space. "3.14116" is considered to be equal to "03.14116" when the type is xs:float and is different when the type is xs:string. The same applies to sort orders: some datatypes have a full order relation (every pair of values can be compared), other have no order relation at all, and the remaining types have a partial order relation (values cannot always be compared).
TIP: Although future versions of APIs might send these values to the applications, the transformations between parsed, lexical, and value spaces are currently done for the sake of the validation only, and don't impact the values sent by a validating parser.
|  | |
| 3.2. New Lessons |  | 4.2. Whitespace Processing |

Copyright © 2002 O'Reilly & Associates. All rights reserved.